本站 7 月 18 日消息,OpenAI 今日凌晨宣布将在 ChatGPT 中推出一款通用型 AI 智能体,该公司表示该智能体可以帮助用户完成各种基于计算机的任务。

OpenAI 介绍称,该智能体可以自动生成可编辑的演示文稿和幻灯片、查看用户的日历来简要介绍即将到来的客户会议、计划并购买制作家庭早餐的食材,以及运行代码等。
该工具名为 ChatGPT agent,结合了 OpenAI 之前多种智能体工具的功能,包括 Operator 点击网站的能力,以及 Deep Research 从数十个网站中综合信息生成简洁研究报告的能力。OpenAI 表示用户只需通过自然语言提示 ChatGPT 即可与该智能体进行交互。
为了开发这个新工具,OpenAI 将其背后的 Operator 和 Deep Research 团队合并为一个统一的团队。外媒 The Verge 报道称,这个新团队由产品和研究部门共 20~35 人组成。

OpenAI 表示 ChatGPT 智能体比其之前的任何产品都要强大得多,可以访问 ChatGPT 连接器,允许用户连接像 Gmail 和 GitHub 这样的应用,智能体可以根据用户的提示找到相关信息。此外,OpenAI 表示 ChatGPT 智能体可以访问终端,并可以使用 API 来访问某些应用。
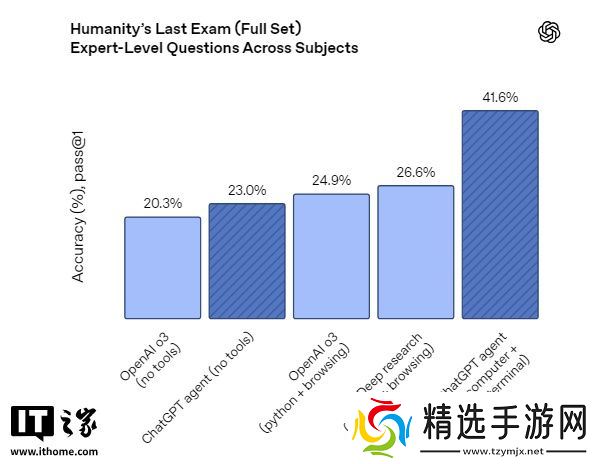
根据 OpenAI 的说法,ChatGPT 智能体的底层模型在多个基准测试中提供了最先进的性能。ChatGPT 智能体模型在 Humanity"s Last Exam(pass@1)中得分率为 41.6%,这是一项由数千个问题组成的、涵盖超过一百个学科的困难测试。这个分数大约是 OpenAI o3 和 o4-mini 得分的两倍。
在已知最难的数学基准测试之一 FrontierMath 中,OpenAI 表示,当 ChatGPT 智能体可以访问工具(本站注:如用于代码执行的终端)时,其得分为 27.4%,之前的最佳分数来自 o4-mini(得分仅为 6.3%)。
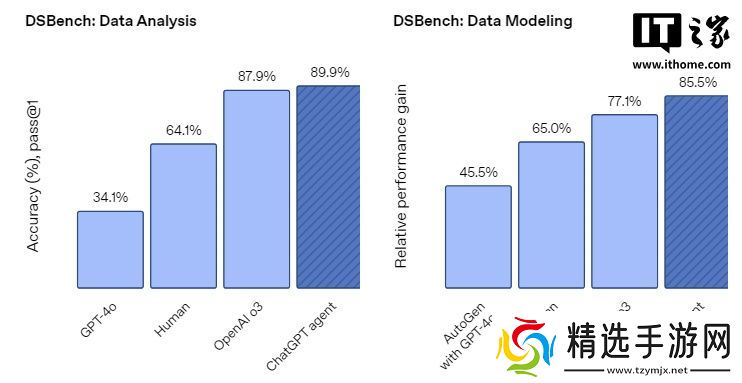
在 DSBench 测试中,该测试旨在评估智能体在涵盖数据分析和建模等现实数据科学任务中的表现,ChatGPT 智能体显著超越了之前的最先进模型 —— 尤其在数据分析任务中,其表现明显优于人类水平。
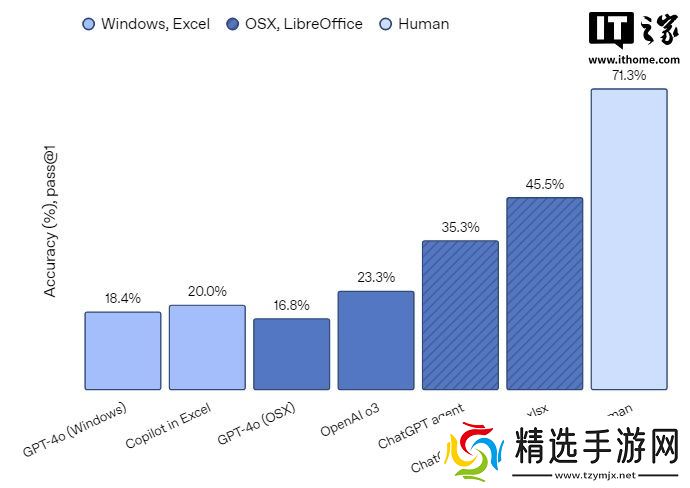
在 SpreadsheetBench 平台上,该平台通过评估模型在处理基于真实世界场景的电子表格编辑任务时的表现来进行评分,ChatGPT 智能体创下了新的行业领先水平(SOTA),其性能较当前行业领先的 GPT‑4o 提升了超过一倍。当具备直接编辑电子表格的能力时,ChatGPT 智能体的得分进一步提升至 45.5%,与 Excel 中 Copilot 的 20.0% 相当。
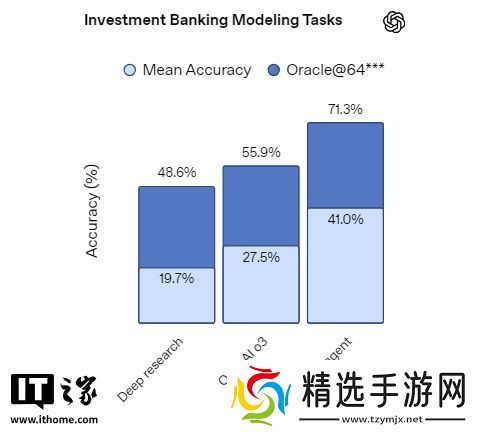
在内部基准测试中,该模型展现了其处理投资银行分析师(1 至 3 年经验)任务的能力,例如为《财富》500 强企业构建符合规范的财务报表模型(包括格式和引用),或为私有化交易构建杠杆收购模型。ChatGPT 智能体所采用的模型在该测试中显著优于深入研究和 o3 模型。每个任务均根据数百项与正确性和公式使用相关的标准进行评分。
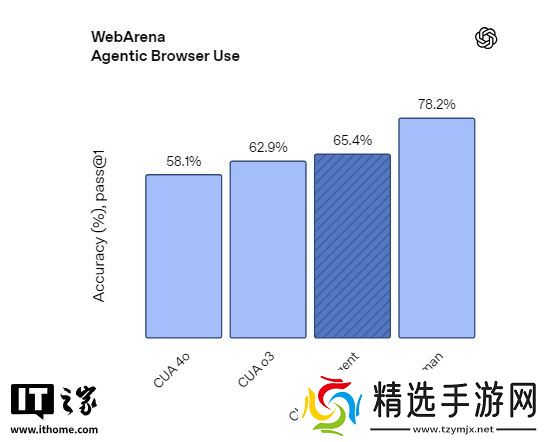
在 WebArena 基准测试中(该测试旨在评估网络浏览智能体在完成真实世界网络任务时的性能),该模型相较于由 o3 驱动的 CUA(即驱动 Operator 的模型)表现更佳。
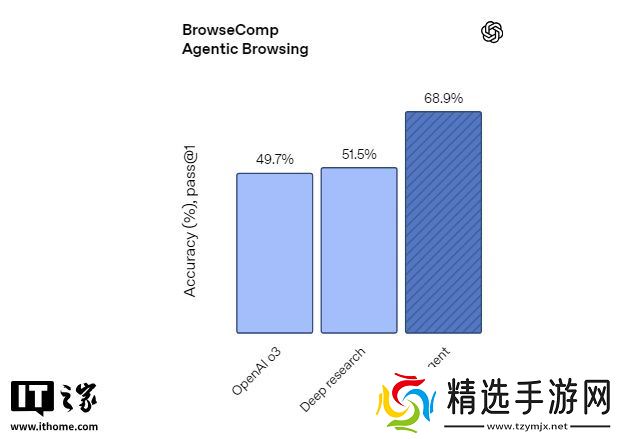
ChatGPT 智能体在 BrowseComp 上的表现方面(OpenAI 今年早些时候发布的基准测试),用于衡量浏览智能体在网络上查找难以找到的信息的能力。该模型以 68.9 的成绩创下了新的 SOTA 纪录,比深入研究高出 xx 个百分点。
具体使用场景方面:
在工作中,用户可以自动处理重复性任务,例如将截图或面板转换为由可编辑矢量元素组成的演示文稿、重新安排会议、规划并预订外出活动,以及在保持原有格式的同时,用新的财务数据更新电子表格。
在个人生活中,用户可以规划并预订旅行行程、设计并预订整个晚宴活动,或寻找专业人士并安排预约。
安全方面,OpenAI 表示用户将始终掌握控制权。ChatGPT 在执行重要操作前会先征得用户的许可,用户可随时中断操作、接管浏览器或停止任务。
用户可以通过编辑器中的工具下拉菜单直接激活 ChatGPT 的新智能体功能,只需在任何对话的任何阶段选择“智能体模式”即可。只需描述希望完成的任务 —— 无论是进行深入研究、制作幻灯片,还是提交费用报销。在执行任务时,屏幕上的语音播报会实时展示 ChatGPT 的具体操作流程。用户可随时中断并接管浏览器操作,确保任务始终与目标保持一致。
此外,用户可设置已完成的任务自动重复执行,例如每周一早上自动生成周度指标报告。
ChatGPT 智能体即日起向 Pro、Plus 和 Team 版用户开放,Enterprise 和 Education 版用户将于 7 月获得使用权限。Pro 版用户每月可执行近乎无限的任务,其他付费用户每月可执行 50 次任务,额外使用量可通过灵活的积分额度选项获取。
OpenAI 表示,ChatGPT 智能体仍处于早期阶段 —— 它能够处理多种复杂任务,但仍可能出现错误。尽管官方认为该功能在生成幻灯片方面具有巨大潜力,但目前该功能仍处于测试阶段 —— 当前生成的内容在格式和细节处理上可能显得较为粗糙,尤其是在没有现有文档的情况下开始创建时。此外,尽管目前您可以上传现有电子表格供 ChatGPT 编辑或作为模板使用,但此功能尚未适用于幻灯片。
OpenAI 正在训练 ChatGPT 幻灯片创建功能的下一代版本,以生成更精致、更复杂的输出,并具备更广泛的功能和改进的格式化能力。
OpenAI 计划以定期的节奏逐步添加重大改进,并使 ChatGPT 智能体随着时间的推移对更多人越来越有用。
